
Organizações de todos os setores sofrem perdas de centenas de milhares de dólares em receitas e redução da produtividade anualmente devido ao tempo de inatividade das redes. De acordo com um estudo de 2014 do Gartner, o custo médio de uma inatividade na rede pode ser de até $ 5,600 por minuto, o que extrapola bem mais de $300 mil por hora. Estas inatividades nas redes e seu impacto na organização são riscos que não devem ocorrer.
Como um administrador de rede, você precisa selecionar o Network Management System (NMS) certo que pode ajudá-lo a resolver rapidamente problemas de rede e monitorar proativamente o desempenho da rede. Os recursos do NMS deve ajudá-lo a evitar desastres de rede e solucionar problemas de rede comuns. Idealmente, o NMS ou a ferramenta de monitoramento de desempenho de rede deve fornecer:
- Um dashboard eficaz para proporcionar visibilidade instantânea da saúde da rede
- Um recurso para automatizar tarefas de rotina
- Uma recurso de análise de causa raiz para isolar problemas entre a rede e o servidor
Recurso matador #1: Um dashboard eficaz para proporcionar visibilidade instantânea da saúde da rede
Às vezes, como um administrador de rede, você pode se sentir sobrecarregado para monitorar em tempo real as várias interfaces da rede em vários locais. Um dashboard eficaz irá fornecer visibilidade em tempo real na rede e irá ajudá-lo a identificar problemas instantâneamente. Ele deve fornecer visualizações em tempo real, incluindo mapas com visões geográficas, visualização da arquitetura lógica e do rack do servidor (para visualizar o datacenter).
Essa informação vai certamente ajudar os administradores de TI a entender as falhas de um nível superior. Por exemplo, se uma porta do switch relata alta utilização de banda larga, você vai precisar analisar as estatísticas de utilização ao vivo para essa porta. Para isso, os administradores de rede fazem o ping através do CMD para verificar o status dos dispositivos de rede. Por outro lado, se o seu dashboard oferece visão em tempo real da rede, você vai ser capaz de visualizar os dispositivos e interfaces imediatamente. Estes gráficos em tempo real no dashboard também fornecem informações detalhadas sobre o desempenho da rede e da sua saúde.
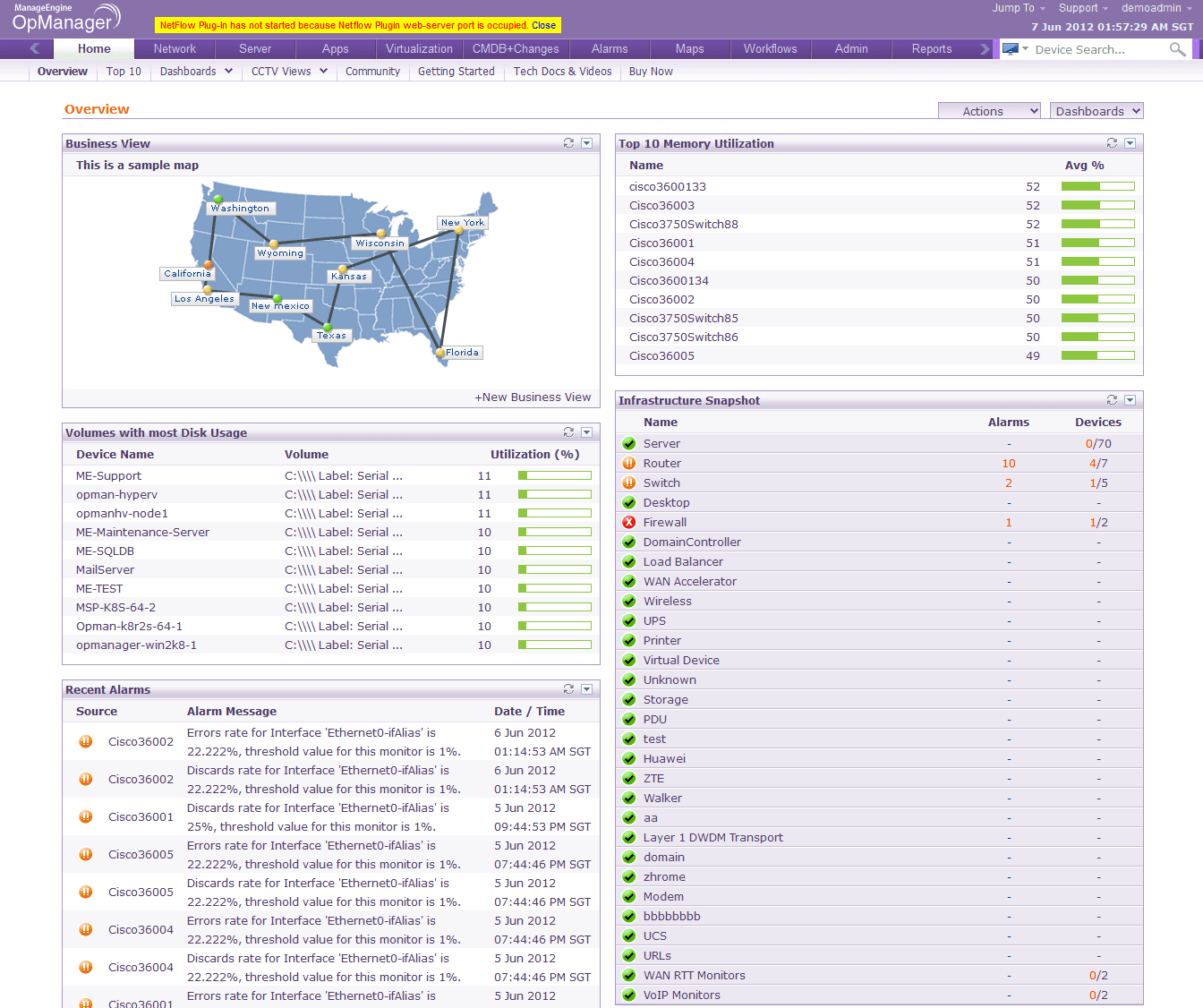
Um dashboard que lista os top 10 melhores dispositivos com utilização de largura de banda ou com alta utilização da CPU ajudam a priorizar os dispositivos ou servidores que devem ser monitorados. Dessa forma, você pode reduzir o tempo de retorno e identificar problemas na rede ou no dispositivo muito antes de seu chefe ou antes que um ticket seja aberto pelos usuários finais.
Recurso matador #2: Um recurso para automatizar tarefas de rotina
Você precisa executar tarefas de rotina ao resolver falhas de rede ou como parte das tarefas de manutenção? Um recurso de remediação de falhas pode ajudar você a automatizar a solução de problemas de primeiro nível e as tarefas de manutenção repetitivas. Você pode facilmente incorporar scripts externos ou automatizar fluxos de trabalho quando ocorrer uma falha de rede ou como parte das tarefas de manutenção.
Esses scripts podem ser executados periodicamente para verificar se há conexões de rede com defeito ou para monitorar outros parâmetros de saúde de rede, como alto uso de CPU ou uma queda da VPN. Os fluxos de trabalho automatizados ou scripts externos incorporados podem executar várias tarefas, que vão desde o envio de mensagens de notificação e verificação de outros indicadores de status para encerrar tarefas de baixa prioridade. Se necessário, eles também podem mudar a configuração do roteador, reduzindo o tempo médio de reparo (MTTR).
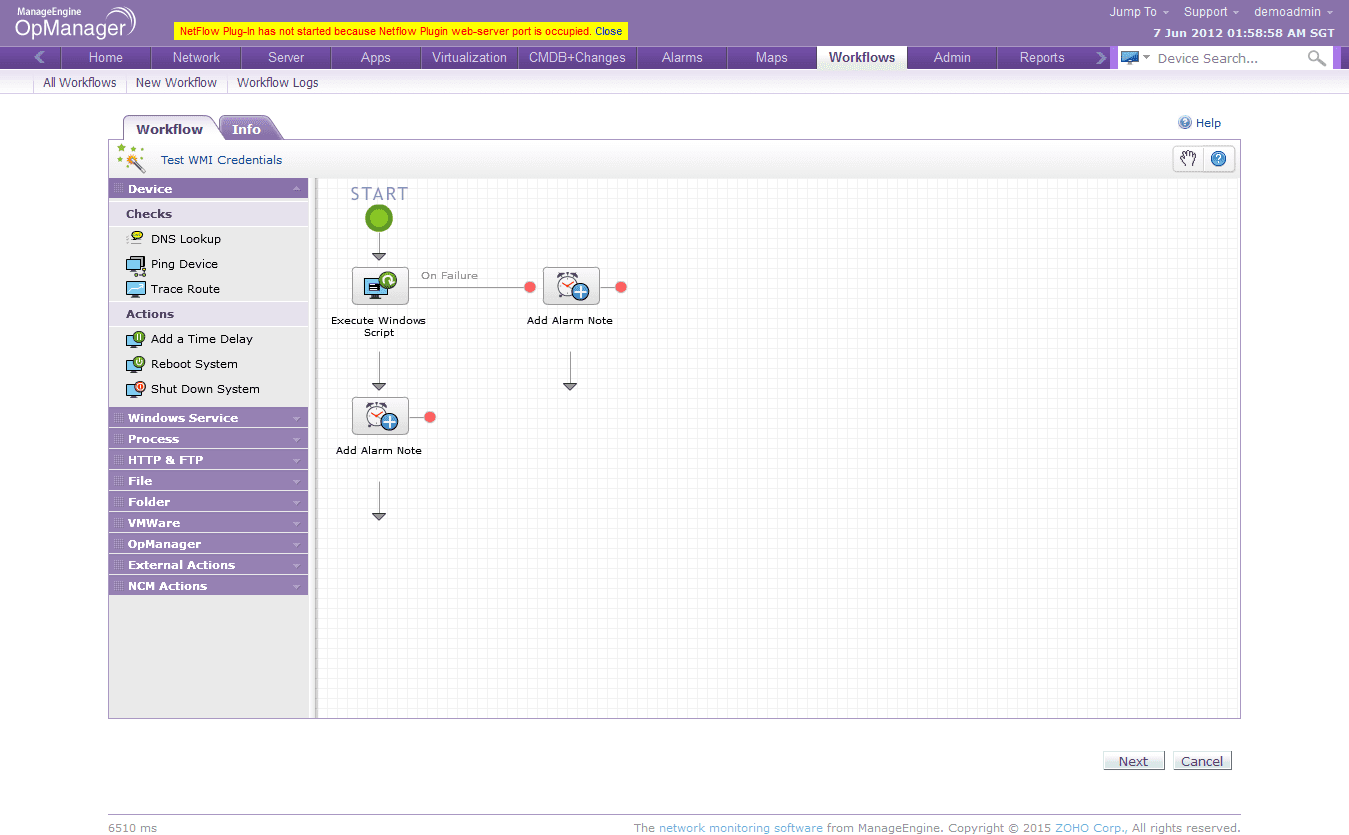
Um recurso de remediação de falhas pode herdar as melhores práticas da infra-estrutura de TI e utilizar um método comprovado para lidar com incidentes e problemas. Além disso, um recurso de automação de fluxo de trabalho pode ajudar a reduzir substancialmente as atividades de apoio e os custos operacionais relacionados.
Recurso matador #3: Uma recurso de análise de causa raiz para isolar problemas entre a rede e o servidor
Apesar de lidar com problemas de rede recorrentes, isolando o servidor ou problemas relacionados com a rede pode ajudá-lo a resolver os tickets rapidamente. O recurso de análise de causa raiz (RCA) ajuda você a fazer exatamente isso. Por exemplo, na maioria das vezes se um aplicativo fica lento, a rede é culpada. No entanto, um aplicativo pode ficar lento devido a outras razões, tais como mudanças de configuração incorreta, os backups do servidor que ocorrem durante as horas de produção, resposta lenta a partir de servidores de banco de dados, ou devido a perdas de pacotes na rede. Nesses casos, você precisa ter certeza para isolar as questões entre a rede e o servidor.
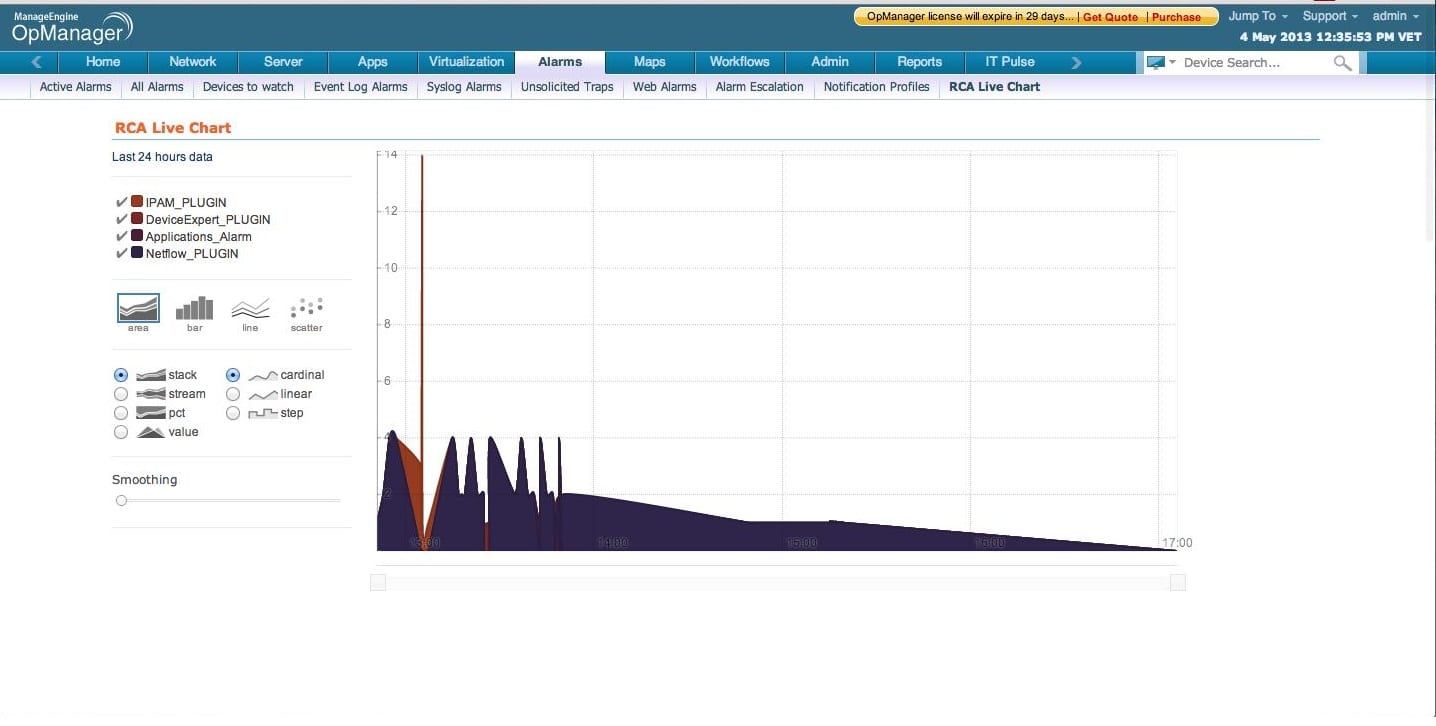 Um recurso de RCA é essencial para determinar se a aplicação está lenta devido ao servidor ou a rede. Ele pode ajudar a isolar problemas relacionados a rede ou a servidores, correlacionando os alertas que vêm do monitoramento de rede e servidores. O RCA acelera a resolução de problemas, fornecendo uma visão útil. Além disso, estabelece um conjunto padrão de relações de causa e efeito entre os diferentes elementos da rede e minimiza o tempo de inatividade.
Um recurso de RCA é essencial para determinar se a aplicação está lenta devido ao servidor ou a rede. Ele pode ajudar a isolar problemas relacionados a rede ou a servidores, correlacionando os alertas que vêm do monitoramento de rede e servidores. O RCA acelera a resolução de problemas, fornecendo uma visão útil. Além disso, estabelece um conjunto padrão de relações de causa e efeito entre os diferentes elementos da rede e minimiza o tempo de inatividade.
Com a infinidade de ferramentas NMS disponíveis no mercado, é importante avaliar suas características cuidadosamente antes de escolher uma para a sua organização. Entretanto, certifique-se de escolher um NMS um robusto que oferece muito mais do que apenas o conjunto padrão de recursos. Se lembre de verificar se a sua ferramenta oferece todas estas características para matar seus problemas de inatividade da rede.
Temos a ferramenta ideal, que oferece todos os recursos acima e muito mais, o OpManager. Gostaria de conhecer esse e mais recursos? Entre em contato com o time da ACSoftware que teremos o prazer em lhe ajudar.
ACSoftware / Figo Software seu Distribuidor e Revenda ManageEngine no Brasil – Fone (11) 4063 1007 – Vendas (11) 4063 9639


{kind=link}