
Anteriormente, apresentamos os 8 KPIs que são críticos para cada help desk de TI. Esses KPIs ajudam a atender a objetivos básicos de help desk de TI, como continuidade de negócios, produtividade organizacional e entrega de serviços no prazo e dentro do orçamento. A postagem anterior do blog discutiu sobre o KPI :taxa de sucesso de mudanças. Este post discute o terceiro KPI – Estabilidade da infraestrutura.
Definição: Uma infraestrutura altamente estável é caracterizada pela disponibilidade máxima, poucas falhas e baixas interrupções no serviço.
Objetivo: Manter uma infraestrutura altamente estável.
Para avaliar e monitorar efetivamente a estabilidade da infraestrutura, os help desks de TI precisam monitorar o seguinte:
- Redução percentual do número de ativos problemáticos.
- Redução percentual do número de incidentes maiores.

Estabilidade das infraestruturas: Redução percentual do número de ativos problemáticos
Oferecer máxima disponibilidade e melhor qualidade de serviço será impossível em uma infraestrutura onde os roteadores devem ser reiniciados várias vezes ao dia, os servidores são frequentemente desativados ou as estações de trabalho precisam ser reiniciadas de vez em quando. Portanto, esses ativos problemáticos devem ser identificados e substituídos para garantir a continuidade dos negócios. Um ativo problemático pode ser repetidamente a causa de interrupções de serviço ou quedas, e para fins de relatórios, estes poderiam ser ativos que têm mais do que alguns incidentes associados a eles. A redução percentual do número de ativos problemáticos pode ser calculada usando a seguinte fórmula:
Número de ativos problemáticos substituídos no final do período.
——————————————————————————
Número de ativos problemáticos identificados no início do período.
Estabilidade das infraestruturas: Redução percentual do número de incidentes graves
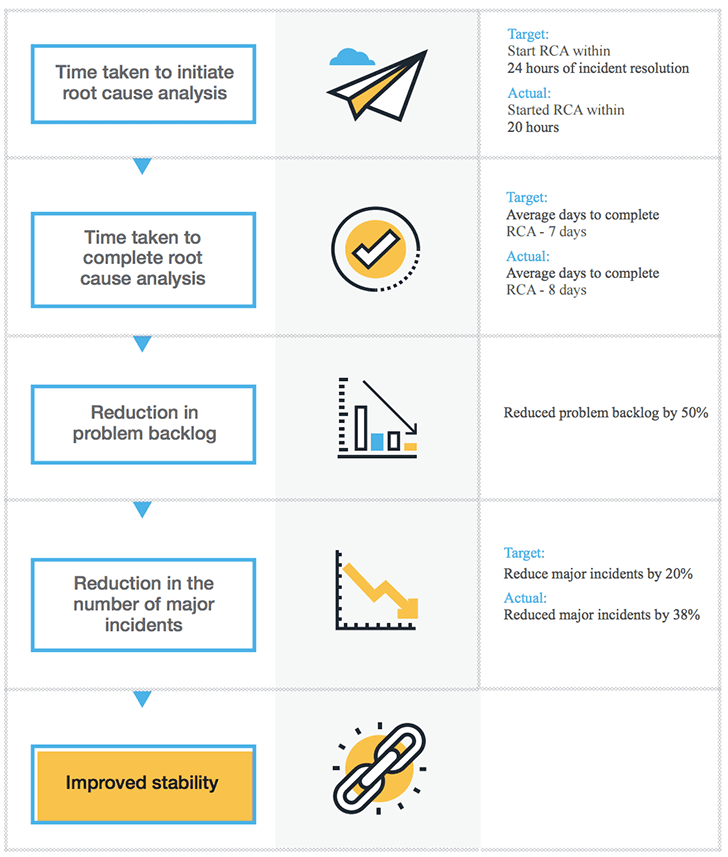
Outra grande indicação de estabilidade é a recorrência de grandes incidentes na infraestrutura de TI, o que pode levar a interrupções no serviço ou deterioração do nível de serviço. Um incidente importante, por definição, é um incidente de alto impacto e alta urgência que afeta um grande número de usuários, privando o negócio de um ou dois serviços-chave. O objetivo é reduzir o número de incidentes graves, o que pode ser conseguido com a análise de causa raiz (RCA) eficiente e com a redução de acúmulo de problemas. Identificar causas raiz e corrigir problemas podem reduzir a recorrência de incidentes maiores e, posteriormente, diminui o volume de tickets para o help desk de TI.
Dicas para reduzir o acúmulo de problema (e, portanto, incidentes importantes)
- Iniciação mais rápida do RCA: Neste caso, quanto mais cedo melhor. Quanto mais cedo o RCA é iniciado, maiores as chances são de identificar a causa raiz.
- Conclusão rápida das investigações: Se a causa raiz for identificada mais rapidamente, a equipe de TI pode corrigir e resolver o problema mais rapidamente, certificando-se de que os incidentes não voltem a ocorrer.
As equipes também podem medir essas ações com detalhes sobre o tempo necessário para iniciar a análise da causa raiz após a identificação do problema e o tempo necessário para concluir a análise da causa raiz.
As principais razões para acúmulo de problemas graves poderia ser:
- Atrasos e RCAs atrasados.
- Qualidade inconsistente de RCAs e falta de documentação adequada.
- Não comunicar eficazmente o processo de investigação aos stakeholders.
Sem identificar e corrigir a causa raiz, as chances de incidentes graves recorrentes são bastante elevados. Felizmente, o acúmulo de problema pode ser reduzido por:
- Ter uma equipe dedicada ao gerenciamento de problemas com administradores de problemas e gerenciadores de problemas.
- Identificação e treinamento de especialistas.
- Treinar a equipe de gerenciamento de problemas sobre as técnicas básicas e avançadas de análise de causa raiz.
Trabalhar nessas duas métricas simples – redução percentual no número de incidentes principais e redução percentual no número de ativos problemáticos – pode ajudá-lo a manter uma infraestrutura de TI altamente estável.
Estudo de caso: Reduzir incidentes importantes ajuda a melhorar a estabilidade da TI
Uma das principais instituições financeiras do mundo conseguiu melhorar sua estabilidade ao reduzir seus principais incidentes. Esta redução no número de incidentes foi conseguida melhorando o seu processo de análise de causa raiz.
![]()



{kind=link}