
O ElasticSearch é um mecanismo de análise e pesquisa RESTful de código aberto distribuído, altamente escalável, que oferece análise de log, monitoramento de aplicativos em tempo real, análise de fluxo de cliques e muito mais. O ElasticSearch armazena e recupera estruturas de dados em tempo real. Ele possui recursos de multi locação com uma interface Web HTTP, apresenta dados na forma de documentos JSON estruturados, torna a pesquisa de texto completa e acessível por meio da API RESTful e mantém clientes da Web para PHP, Ruby, .Net e Java.
A única maneira de aproveitar totalmente esses recursos é usando as ferramentas de monitoramento do ElasticSearch que oferecem uma visibilidade profunda do seu ambiente ElasticSearch. As ferramentas de monitoramento certas do ElasticSearch podem transformar dados em insights acionáveis. Monitorar o desempenho do seu ambiente ElasticSearch com os dados agregados mais recentes ajuda você a manter-se atualizado sobre os componentes internos do cluster em funcionamento. Quando se trata de monitoramento do ElasticSearch, existem várias métricas a serem consideradas – aqui, vamos dar uma olhada mais de perto em quatro métricas importantes que você deve manter em seu radar.
Principais métricas de desempenho do ElasticSearch para monitorar:
1. Saúde do cluster e disponibilidade do node
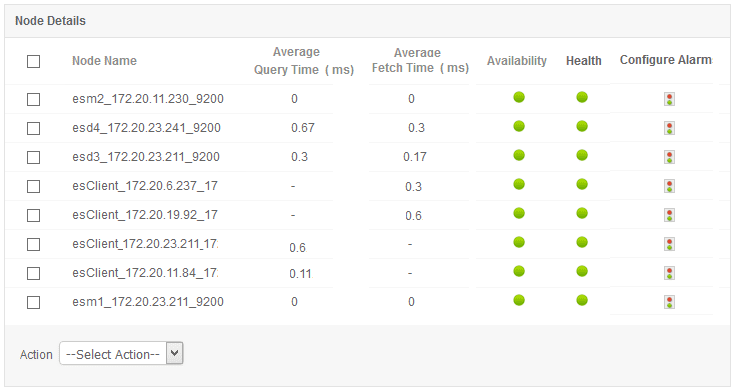
O desempenho de um servidor ElasticSearch depende fortemente da máquina em que ele está instalado. Para manter a integridade do cluster, é essencial monitorar as principais métricas de desempenho, como E / S de disco, uso de CPU para todos os nodes, uso de memória e integridade do node ( em tempo real) para cada nó do ElasticSearch. É melhor olhar para as métricas do Java Virtual Machine (JVM) quando surgem picos de CPU. Como o ElasticSearch é executado dentro da JVM, o monitoramento do uso de memória do ElasticSearch requer que você verifique a memória da JVM e as estatísticas de coleta de lixo.
2. Métrica de Desempenho da Indexação
Ao executar benchmarks de indexação, um número fixo de registros é usado para calcular a taxa de indexação. Quando a carga de trabalho é pesada, a atualização de índices com novas informações torna o monitoramento e a análise do desempenho do ElasticSearch mais fácil. Picos repentinos e quedas nas taxas de indexação podem indicar problemas com as fontes de dados. O desempenho geral do cluster pode ser afetado pelo tempo de atualização e pelo tempo de mesclagem.
Tempos de atualizações reduzidos e tempos de mesclagens rápidas geralmente são preferidos. As ótimas ferramentas de monitoramento de desempenho do ElasticSearch ajudam a monitorar a latência média de consulta de cada node, incluindo a hora de início, o tempo médio do segmento do node, o uso do cache do sistema de arquivos e as taxas de solicitações, além de ajudar a configurar ações se os limites forem violados.
3. Métrica de Desempenho de Pesquisa
Além das solicitações de Indexação, outra solicitação importante é a solicitação de pesquisa. Aqui estão algumas métricas importantes de desempenho de pesquisa a serem consideradas durante a execução do monitoramento do ElasticSearch:
- Consulta de latência e taxa de solicitação: há várias coisas que podem afetar o desempenho da consulta, como consultas mal construídas, clusters ElasticSearch configurados incorretamente, memória da JVM, problemas de coleta de lixo, etc. Sem dúvida, a latência da consulta é uma métrica que afeta diretamente nos usuários, e é essencial que você receba alertas quando houver uma anomalia. O rastreamento da taxa de solicitações junto com a latência da consulta fornece uma visão geral de quanto um sistema é usado.
Cache de filtro: os filtros no ElasticSearch são armazenados em cache por padrão. Ao executar uma consulta com um filtro, o ElasticSearch encontrará documentos correspondentes ao filtro e construirá uma estrutura chamada bitset usando essa informação. Se as execuções subsequentes da consulta tiverem o mesmo filtro, as informações armazenadas no bitset serão reutilizadas, tornando a execução da consulta mais rápida, salvando as operações de E / S e os ciclos da CPU.
4. Monitoramento do pool de redes e threads
Os nodes do ElasticSearch usam conjuntos de encadeamentos para gerenciar a memória de encadeamentos e o consumo de CPU. Conjuntos de encadeamentos são configurados automaticamente com base no número de processadores. Os conjuntos de encadeamentos importantes a serem monitorados incluem: pesquisa, indexação, mesclagem e em massa. Os problemas do conjunto de encadeamentos podem ser causados por um grande número de solicitações pendentes ou por um único node lento, bem como por uma rejeição do conjunto de encadeamentos. Uma mudança drástica no uso da memória ou na coleta de lixo longa pode indicar uma situação crítica.
Muitas atividades de coleta de lixo podem acontecer por dois motivos:
Uma pool particular está alterado.
A JVM precisa de mais memória do que o que foi alocado para ela.
Para evitar picos em seu conjunto de thread, esteja preparado para os problemas de threads causados por solicitações pendentes.
O ManageEngine Applications Manager facilita o monitoramento do ElasticSearch oferecendo monitoramento imediato para seu servidor ElasticSearch com insights profundos que identificam facilmente os nodes problemáticos com a análise da causa-raiz dos problemas de desempenho.
Comece a monitorar seu servidor ElasticSearch agora mesmo realizando os testes de 30 dias totalmente gratuito e completo do Application Manager, contando sempre com o apoio da equipe ACSoftware, sua revendedora ManageEngine no Brasil!



{kind=link}